| 多变量时间序列的预测和建模指南(附Python代码) | 您所在的位置:网站首页 › vector ar › 多变量时间序列的预测和建模指南(附Python代码) |
多变量时间序列的预测和建模指南(附Python代码)
|
时间是决定企业兴衰的最关键因素。这就是为什么我们看到商店和电子商务平台的销售与节日一致。这些企业分析多年的消费数据,以了解打开大门的最佳时间,并看到消费支出的增加。 但是,作为一个数据科学家,你怎么能进行这种分析呢?别担心,你不需要建造一台时间机器!时间序列建模是一种强大的技术,是理解与预测趋势和模式的门户。
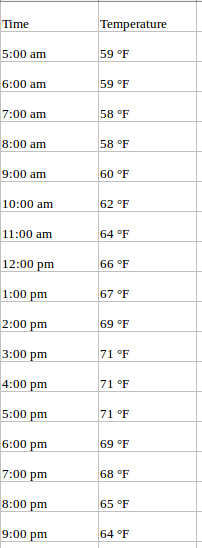
但是即使是时间序列模型也有不同的方面。我们在Web上看到的大多数例子都是用单变量时间序列来处理的。不幸的是,现实世界的用例并不是这样工作的。有多个变量在起作用,同时处理所有这些变量是数据科学家体现其价值的地方。 在这篇文章中,我们将了解什么是多元时间序列,以及如何处理它。我们还将在Python中进行案例研究并实现它,以使您对该主题有实际的理解。 目录表 单变量与多变量时间序列— —单变量时间序列 — —多元时间序列 多变量时间序列-向量自回归(VAR)的处理 为什么我们需要VAR? 多变量时间序列的平稳性 训练验证拆分 Python实现 1.单变量与多变量时间序列本文假定读者熟悉单变量时间序列的性质,以及用于预测的各种技术。由于本文将重点讨论多变量时间序列,因此我建议您阅读以下文章,这些文章可以作为对单变量时间序列的良好介绍: 时间序列预测综合指南 使用Auto ARIMA构建高性能时序模型但是,在讨论多元时间序列的细节之前,我将快速地介绍一下什么是单变量时间序列。让我们逐一观察它们的差异。 1.1单变量时间序列 一个单变量时间序列,顾名思义,是一个具有单一时间依赖变量的序列。 例如,在过去的2年中,查看下面的样本数据集,该数据集包括温度值(每小时)。这里,温度是因变量(取决于时间)。
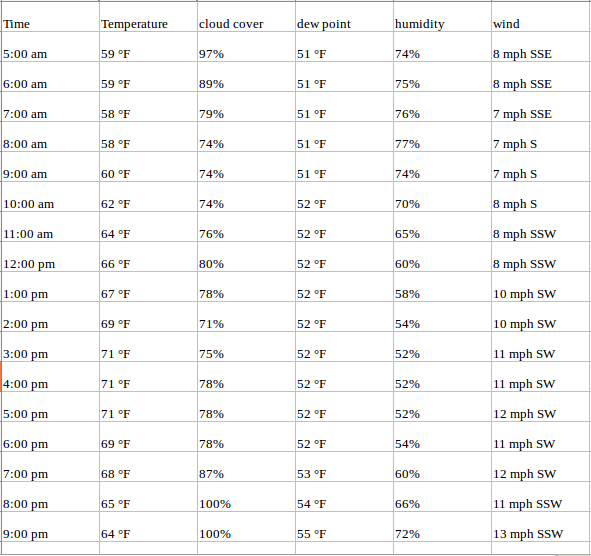
如果要求我们预测未来几天的温度,我们将查看过去的值,并尝试测量和提取一个模式。我们会注意到早晨和晚上的温度较低,下午则达到峰值。此外,如果你有过去几年的数据,你会发现,在11月到1月份,天气比较冷,而在4月至6月比较热。 这样的观察将有助于我们预测未来的价值观。你注意到我们只使用了一个变量(过去2年的温度)吗?因此,这被称为单变量时间序列分析/预测。 1.2多元时间序列(MTS) 多变量时间序列具有一个以上的时间依赖变量。每个变量不仅取决于其过去的值,而且还对其他变量有一定的依赖性。这种依赖性用于预测未来的价值。听起来很复杂?让我解释一下。 考虑上面的例子。现在假设我们的数据集包括过去两年的汗水百分比、露点、风速、云层覆盖率等,以及温度值。在这种情况下,有多个变量被认为是最佳预测温度。像这样的系列将属于多元时间序列的范畴。下面是一个例证:
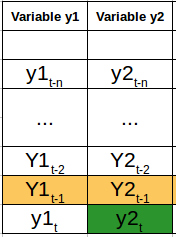
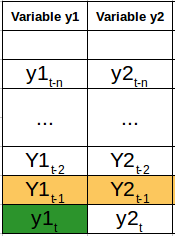
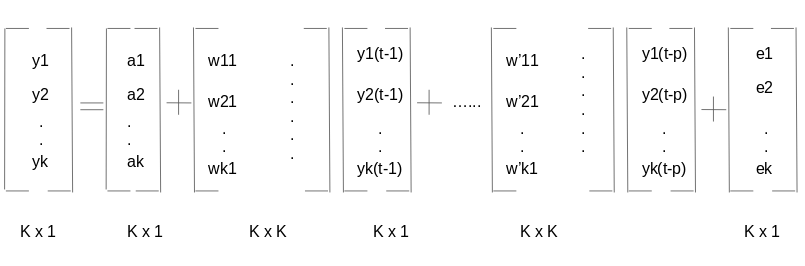
现在我们了解了多元时间序列的样子,让我们了解如何利用它来建立预测。 2.多元时间序列的处理——VAR在本节中,我将介绍多变量时间序列预测中最常用的方法之一——向量自回归(VAR)。 在VAR模型中,每个变量是其自身过去值和所有其他变量的过去值的线性函数。为了更好地解释这一点,我将使用一个简单的视觉例子: 我们有两个变量y1和y2。我们需要从过去N值的给定数据预测时间t上的这两个变量的值。为了简单起见,我已经考虑滞后值为1。
为了计算y1(t),我们将使用y1和y2的过去值。类似地,为了计算y2(t),将使用y1和y2的过去值。下面是表示这种关系的简单数学方法:
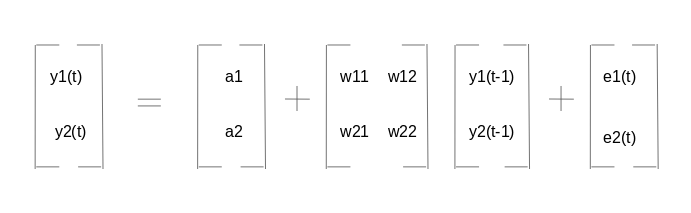
在这里,a1和a2是常数项,w11、w12、w21和w22是系数,e1和e2是误差项。 这些方程类似于AR方程的过程。由于AR过程用于单变量时间序列数据,所以未来值只是它们自己的过去值的线性组合。考虑AR(1)过程: y(t) = a + w*y(t-1) +e 在这种情况下,我们只有一个变量—y、常数项—a、误差项—e和系数—w。为了适应VAR的每个方程中的多变量项,我们将使用向量。我们可以用下列形式写出方程式(1)和(2):
这两个变量是Y1和Y2,其次是常数、系数度量、滞后值和误差度量。这是VAR(1)过程的向量方程。对于VAR(2)过程,将另一个时间向量项(T-2)加入到方程中,以推广P滞后:
上述方程表示具有变量y1、y2…yk的var(p)过程。同样可以写成:
方程中εt表示多元矢量白噪声。对于一个多变量时间序列,εt应该是满足下列条件的连续随机向量: 1.E(εt)=0 误差向量的期望值为0。 2.E(εt1,εt2′)=12 εt和εt′的期望值是级数的标准偏差。 3.我们为什么需要VAR?回想一下我们早些时候看到的温度预测例子,可以将其作为一个多变量单变量序列进行讨论。我们可以使用简单的单变量预测方法如AR来解决这个问题,因为其目的是预测温度,所以我们可以简单地去除其他变量(除了温度),并在剩余的单变量序列上拟合一个模型。 另一个简单的想法是使用我们已经知道的技术来逐个预测每个系列的值。这将使工作非常直截了当!那你为什么还要学习另一种预测技术呢?这个话题已经足够复杂了吗? 从上面的方程(1)和(2)可以清楚地看到,每个变量都使用每个变量的过去值来进行预测。与AR不同,VAR能够理解和使用多个变量之间的关系。这有助于描述数据的动态行为,并提供更好的预测结果。此外,实现VAR与使用任何其他单变量技术一样简单(您将在最后一节中看到)。 4.多变量时间序列的平稳性通过研究单变量概念,我们知道,平稳时间序列往往会给我们一组更好的预测。如果您不熟悉平稳性的概念,请先阅读本文:处理非平稳时间序列的温和介绍。 总之,对于给定的单变量时间序列: y(t) = c*y(t-1) + ε t 如果c<1,则该级数是固定的。现在,回忆一下我们的VAR过程方程:
注:I 是单位矩阵。 用滞后算子表示方程,我们有:
在左边的所有y(t)项:
y(t)的系数称为滞后多项式。让我们把这个表示为(L):
对于一系列不动点,π(L)- 1π的特征值应小于1。考虑到派生变量的数量,这可能看起来很复杂。这个想法已经在视频中用一个简单的数值例子来解释。我高度鼓励看它巩固你的理解。 类似于单变量序列的增强Dickey-Fuller检验,我们有用来检验任何多变量时间序列数据的平稳性的Johansen检验。我们将在本文的最后一节中看到如何进行测试。 5.训练验证拆分如果你以前使用过单变量时间序列数据,你会知道训练验证集。创建验证集的想法是在使用模型进行预测之前,分析模型的性能。 创建时间序列问题的验证集是棘手的,因为我们必须考虑到时间成分。不能直接使用train_test_split 分割或K-折叠验证,因为这会破坏序列中的模式。应考虑日期和时间值创建验证集。 假设我们必须使用过去两年的数据来预测未来两个月的温带气候、露点、云百分比等。一种可能的方法是把过去两个月的数据放在一边,并在剩下的22个月内训练模型。 一旦模型被训练,我们就可以使用它来对验证集进行预测。基于这些预测和实际值,我们可以检查模型执行得有多好,以及模型没有很好地执行的变量。为了进行最终的预测,使用完整的数据集(训练和验证集相结合)。 6.Python实现在本节中,我们将在玩具数据集上实现向量AR模型。我已经使用了空气质量数据集,你可以从这里下载。 #import required packages import pandas as pd import matplotlib.pyplot as plt %matplotlib inline #read the data df = pd.read_csv("AirQualityUCI.csv", parse_dates=[['Date', 'Time']]) #check the dtypes df.dtypes Date_Time object CO(GT) int64 PT08.S1(CO) int64 NMHC(GT) int64 C6H6(GT) int64 PT08.S2(NMHC) int64 NOx(GT) int64 PT08.S3(NOx) int64 NO2(GT) int64 PT08.S4(NO2) int64 PT08.S5(O3) int64 T int64 RH int64 AH int64 dtype: objectDate_Time列的数据类型是Object,我们需要将其更改为datetime。此外,为了准备数据,我们需要索引具有datetime。遵循以下命令: df['Date_Time'] = pd.to_datetime(df.Date_Time , format = '%d/%m/%Y %H.%M.%S') data = df.drop(['Date_Time'], axis=1) data.index = df.Date_Time下一步是处理缺失的值。由于数据中缺失的值被替换为值-200,我们将不得不用更好的数字来计算缺失的值。考虑这个——如果当前露点值丢失,我们可以安全地假设它将接近前一个小时的值。有道理,对吧?在这里,我将用前一个值来填充-200。 您可以选择使用前面几个值的平均值来替换该值,或者同时使用前一天的值(您可以在下面的评论区中共享您关于输入缺失值的想法)。 #missing value treatment cols = data.columns for j in cols: for i in range(0,len(data)): if data[j][i] == -200: data[j][i] = data[j][i-1] #checking stationarity from statsmodels.tsa.vector_ar.vecm import coint_johansen #since the test works for only 12 variables, I have randomly dropped #in the next iteration, I would drop another and check the eigenvalues johan_test_temp = data.drop([ 'CO(GT)'], axis=1) coint_johansen(johan_test_temp,-1,1).eig下面是测试的结果: array([ 0.17806667, 0.1552133 , 0.1274826 , 0.12277888, 0.09554265, 0.08383711, 0.07246919, 0.06337852, 0.04051374, 0.02652395, 0.01467492, 0.00051835])现在我们可以继续创建验证集来适应模型,并测试模型的性能: #creating the train and validation set train = data[:int(0.8*(len(data)))] valid = data[int(0.8*(len(data))):] #fit the model from statsmodels.tsa.vector_ar.var_model import VAR model = VAR(endog=train) model_fit = model.fit() # make prediction on validation prediction = model_fit.forecast(model_fit.y, steps=len(valid))预测是数组的形式,其中每个列表代表行的预测。我们将把这个转变成一个更具代表性的格式。 #converting predictions to dataframe pred = pd.DataFrame(index=range(0,len(prediction)),columns=[cols]) for j in range(0,13): for i in range(0, len(prediction)): pred.iloc[i][j] = prediction[i][j] #check rmse for i in cols: print('rmse value for', i, 'is : ', sqrt(mean_squared_error(pred[i], valid[i])))以上代码的输出: rmse value for CO(GT) is : 1.4200393103392812 rmse value for PT08.S1(CO) is : 303.3909208229375 rmse value for NMHC(GT) is : 204.0662895081472 rmse value for C6H6(GT) is : 28.153391799471244 rmse value for PT08.S2(NMHC) is : 6.538063846286176 rmse value for NOx(GT) is : 265.04913993413805 rmse value for PT08.S3(NOx) is : 250.7673347152554 rmse value for NO2(GT) is : 238.92642219826683 rmse value for PT08.S4(NO2) is : 247.50612831072633 rmse value for PT08.S5(O3) is : 392.3129907890131 rmse value for T is : 383.1344361254454 rmse value for RH is : 506.5847387424092 rmse value for AH is : 8.139735443605728在验证集的测试之后,让模型在完整的数据集上拟合 #make final predictions model = VAR(endog=data) model_fit = model.fit() yhat = model_fit.forecast(model_fit.y, steps=1) print(yhat)小结 在我开始这篇文章之前,使用多变量时间序列的想法似乎在其范围内令人望而生畏。这是一个复杂的话题,所以要花时间了解细节。最好的学习方法是练习,所以我希望上面的Python实现会对你有用。 我建议您在您选择的数据集上使用此方法。这将进一步巩固你对这个复杂而又非常有用的话题的理解。如果你有任何建议或疑问,请在评论部分分享。 |
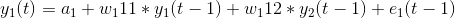
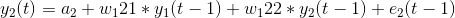
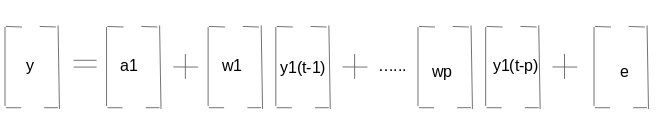
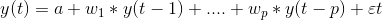
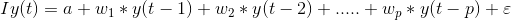
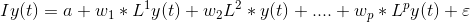
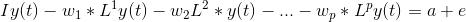
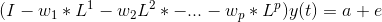
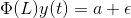
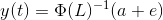
【本文地址】